Create a job using Glue Studio
Planning the Data Transformation Steps
It’s a good practice to plan the steps to transform your data. Based on the information we captured during data exploration stage, we can come up with the following transformation step:
- Read yellow trip data from S3, raw_yellow_tripdata table.
- Clean yellow trip data data.
- Remove records with NULL values (vendorid, payment_type, passenger count, ratecodeid).
- Filter records within a time period (remove records with invalid pickup datetime, narrow down data to be processed).
- Join yellow trip data with taxi zone lookup to obtain pickup location information.
- Read lookup data from S3, raw_taxi_zone_lookup table.
- Rename column names of lookup data to differentiate pickup locations from drop-off locations.
- Perform the join.
- Join yellow trip data with taxi zone lookup to obtain drop-off location information.
- Read lookup data from S3, raw_taxi_zone_lookup table.
- Rename column names of lookup data to differentiate drop-off locations from pickup locations.
- Perform the join.
- Perform data transformation on joined dataset.
- Rename column names.
- Set appropriate data types.
- Remove redundant columns as a result of table joins.
- Save processed dataset to S3 in a query optimized format.
Create a job using Glue Studio
-
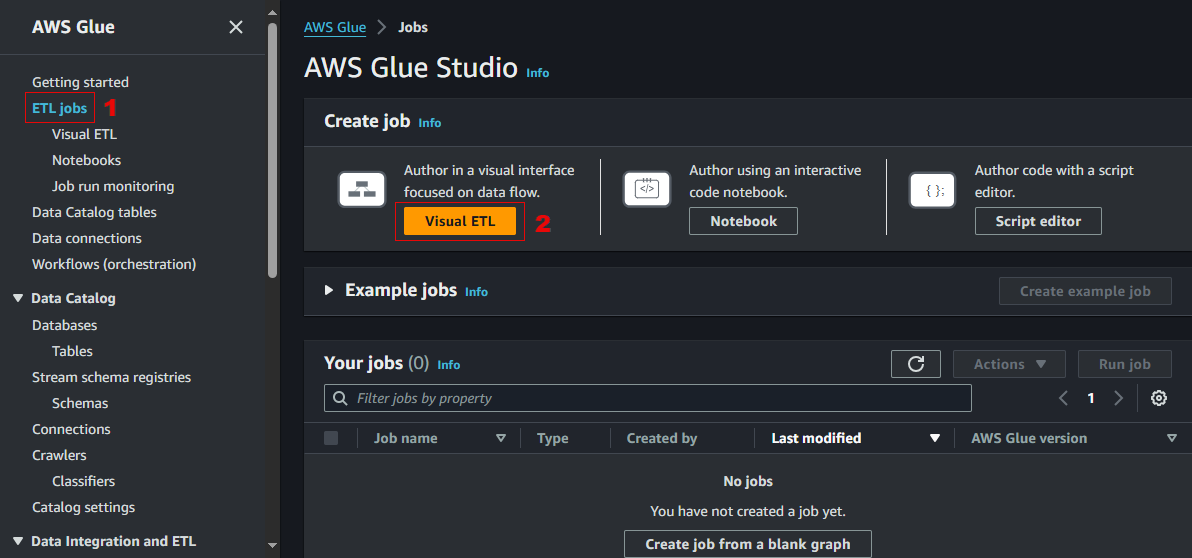
Go to Glue console.
-
In the left navigation panel, click ETL jobs.
-
On the AWS Glue Studio page, click Visual ETL.
-
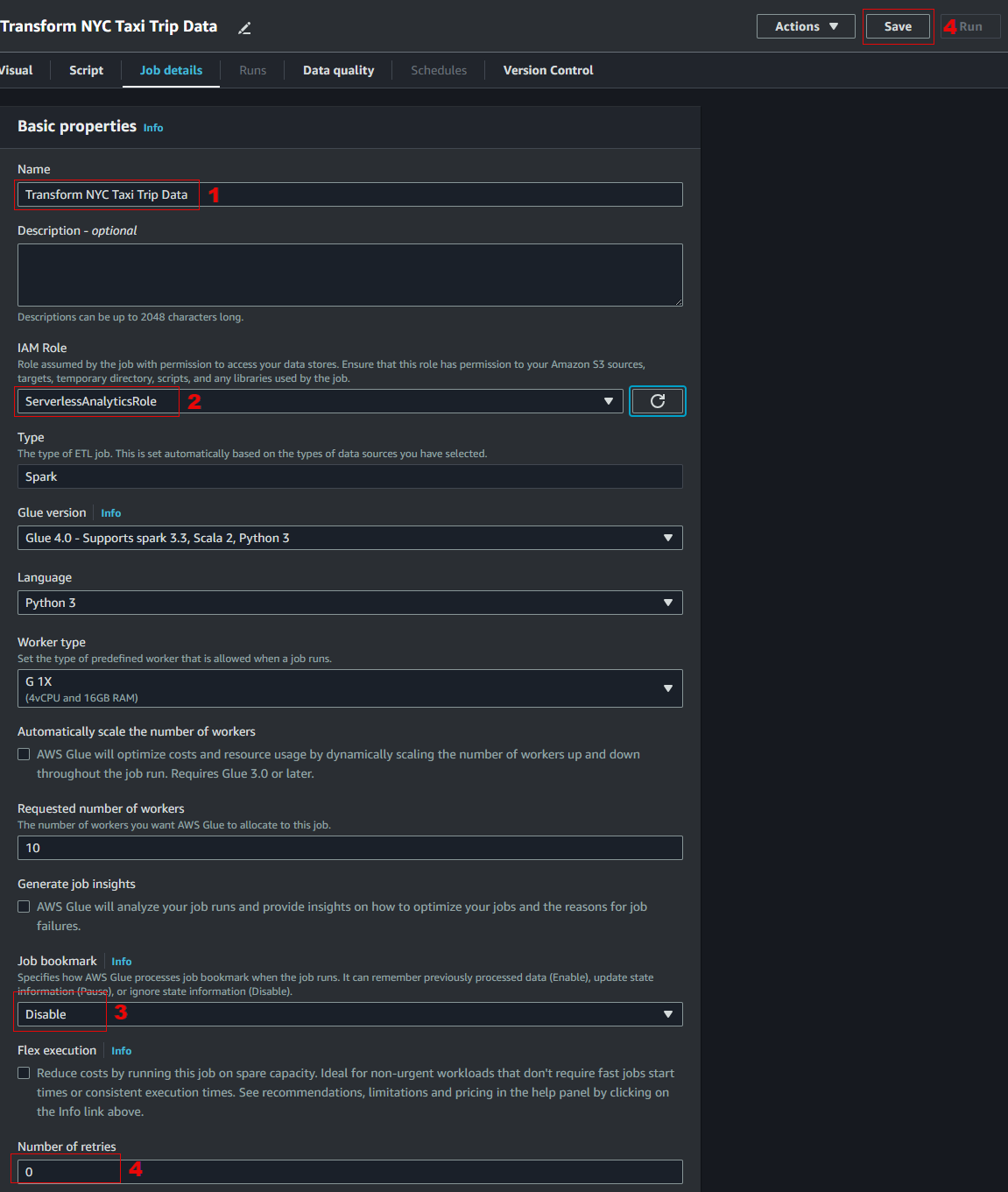
In the Glue Studio editor page, go to the Job details tab, set the following configuration:
- Name –
Transform NYC Taxi Trip Data - IAM Role – ServerlessAnalyticsRole
- Job bookmark – Disable
- Number of retries -
0
AWS Glue job bookmark feature helps maintain state information and prevent the reprocessing of old data. It enables the job to process only new data when rerunning on a scheduled interval.
- Name –
-
Click Save. Go back to the Visual tab.