AWS-Logo_White-Color
1.
Getting Started
2.
Discovering and Cataloging Data
2.1
Create a Glue Crawler
2.2
Run the Glue Crawler
2.3
Review the metadata in Glue Data Catalog
3.
Exploring Data
3.1
Using Amazon Athena for the first time
3.2
Preview table data
3.3
Working with CSV data enclosed in quotes
3.4
Run SQL queries to explore the data
4.
Transforming Data
4.1
Create a job using Glue Studio
4.2
Add a data source
4.3
Remove records with NULL values
4.4
Filter records
4.5
Add another data source
4.6
Join data
4.7
Add and join another dataset
4.8
Transform data and save to target
4.9
Run the job
5.
Enriching Data
5.1
Catalog transformed data
5.2
Validate transformed data
5.3
Enrich transformed data
6.
Visualizing Data
6.1
Using Amazon QuickSight for the first time
6.2
Connect to a data source
6.3
Review dataset
6.4
Visualize data
7.
Clean Up Resources
8.
Summary
More
AWS Study Group - Blog
AWS Study Group - FB Group
English
Tiếng Việt
Clear History
Workshop
Cloud Journey
Last Updated
26-11-2023
Team
Gia Hưng
AWS Serverless Data Lake Jumpstart
>
Discovering and Cataloging Data
> Run the Glue Crawler
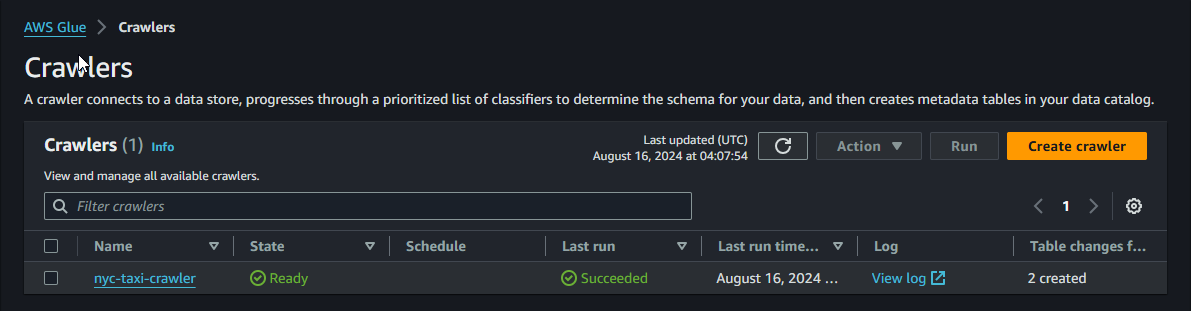
Run the Glue Crawler
Run the Glue Crawler
On the Crawlers page, select
nyc-taxi-yellow-trips-csv-crawler
, and then click
Run crawler
.
Upon successful completion of the crawler, you should see a value of 2 in the Tables added column.