Create a Glue Crawler
Create a Glue Crawler
Glue Crawler is a feature that automatically infer database and table schema from your source data then stores the associated metadata in the AWS Glue Data Catalog.
-
Go to the AWS Glue Console.
-
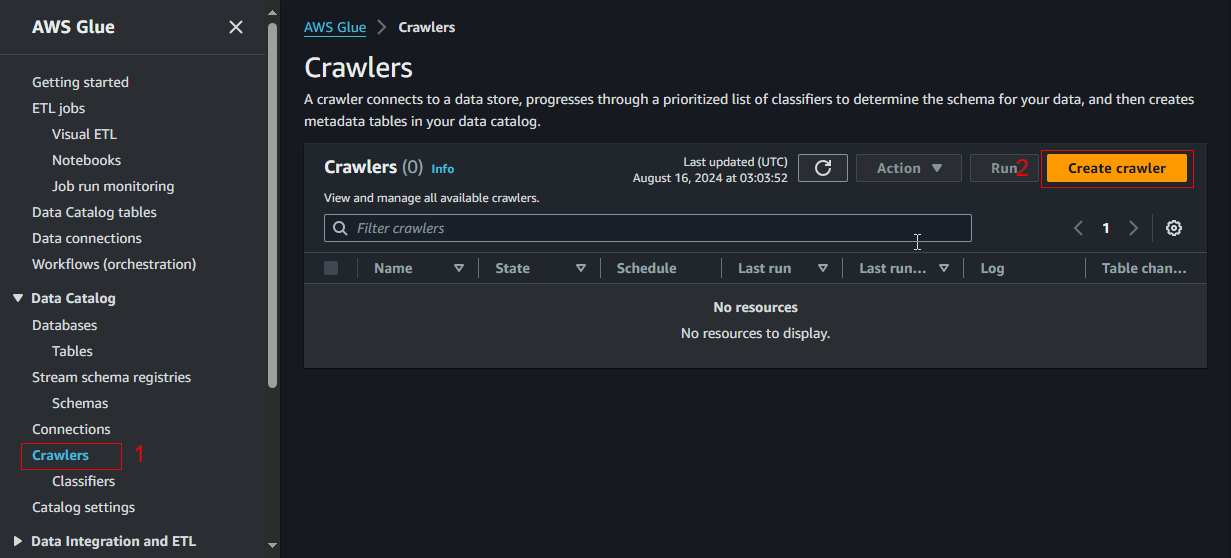
In the left navigation menu, click Crawlers.
-
On the Crawlers page, click Create crawler.
-
Specify
nyc-taxi-crawleras the crawler’s name, click Next. -
On the Choose data sources and classifiers screen, specify the following information, and then click Next.
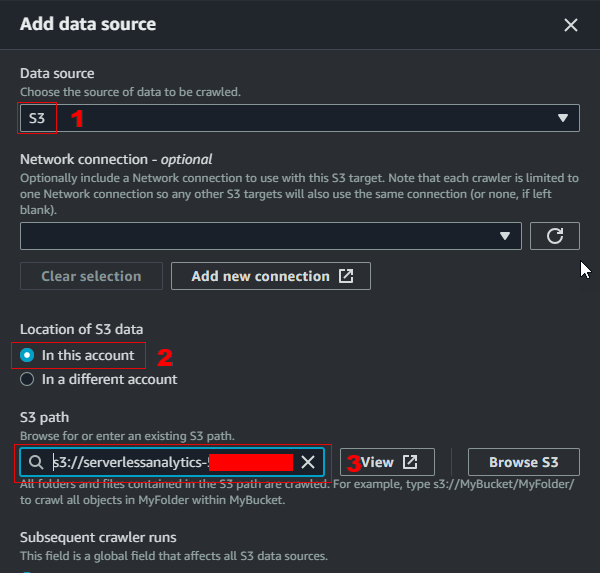
- Click Add a data source
- Choose a Data source – S3
- Select Location of S3 data - In this account
- Include S3 path –
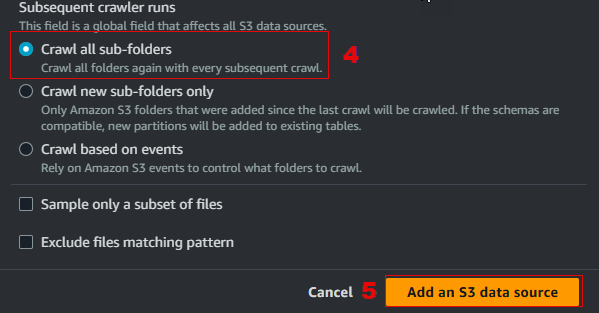
s3://serverlessanalytics-[your-account-id]-raw/nyc-taxi/ - For Subsequent crawler runs, select to Crawl all sub-folders
- Then click Add an S3 data source.
-
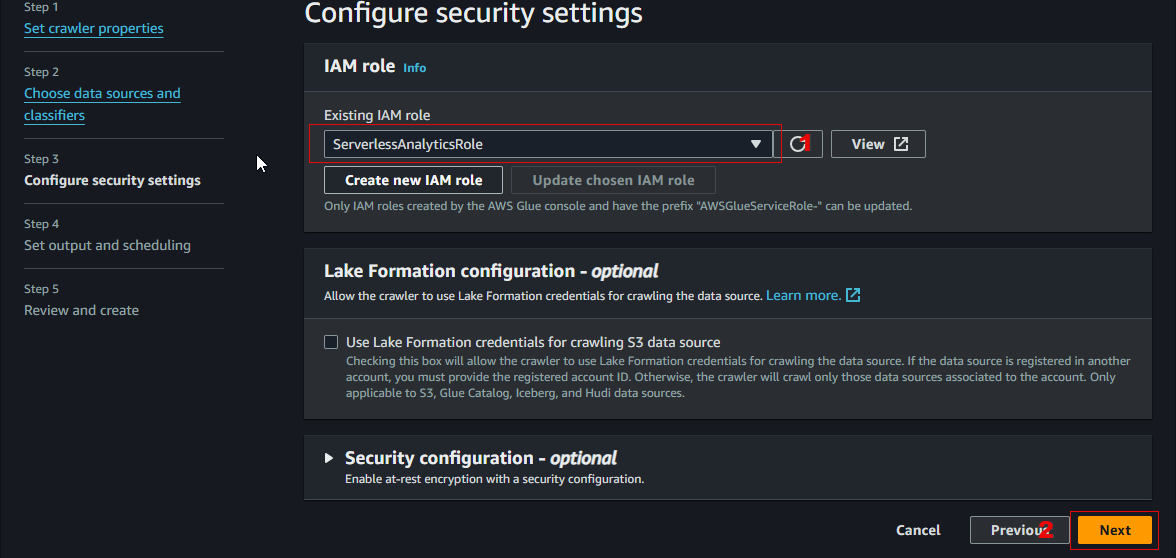
On Configure security settings, choose ServerlessAnalyticsRole from the Existing IAM role, click Next.
-
On the Set output and scheduling screen, click Add database.
-
Specify
nyctaxi_dbas the unique database name, and then click Create database.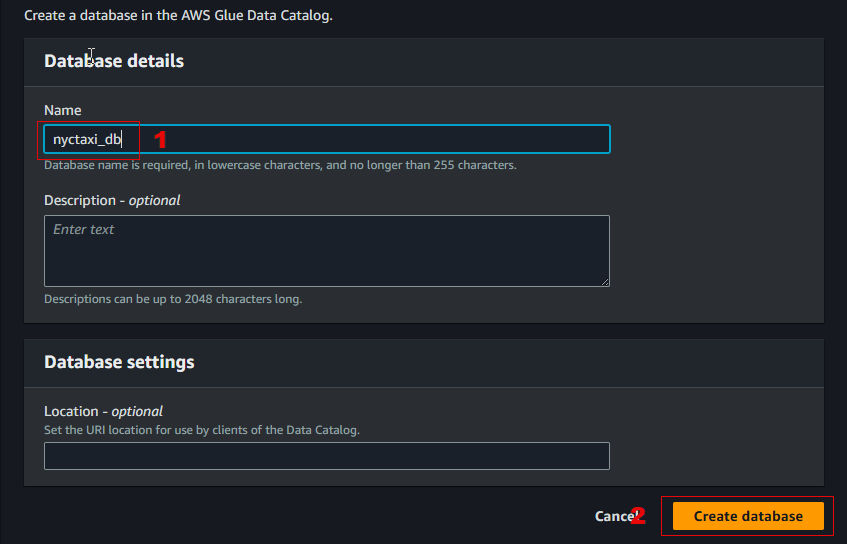
-
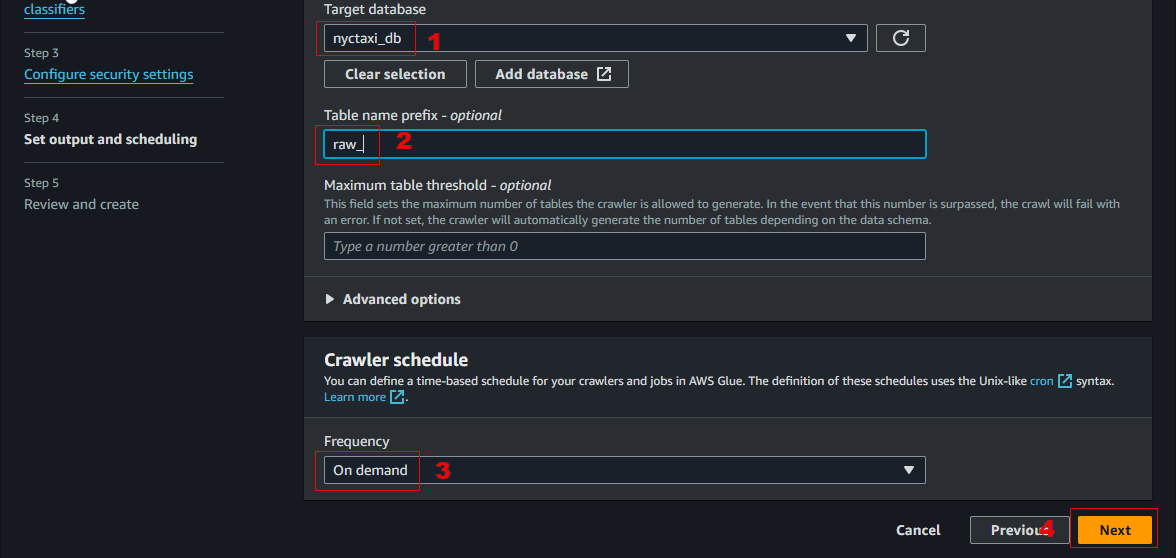
Go back to the previous tab (Set output and scheduling screen), refresh the selection for Target database and choose the newly created database
nyctaxi_db. -
Specify
raw_in the Table name prefix - optional field. -
On the Crawler schedule, leave the frequency On demand, click Next.
- Review the crawler details, click Create crawler.