Discovering and Cataloging Data
Overview
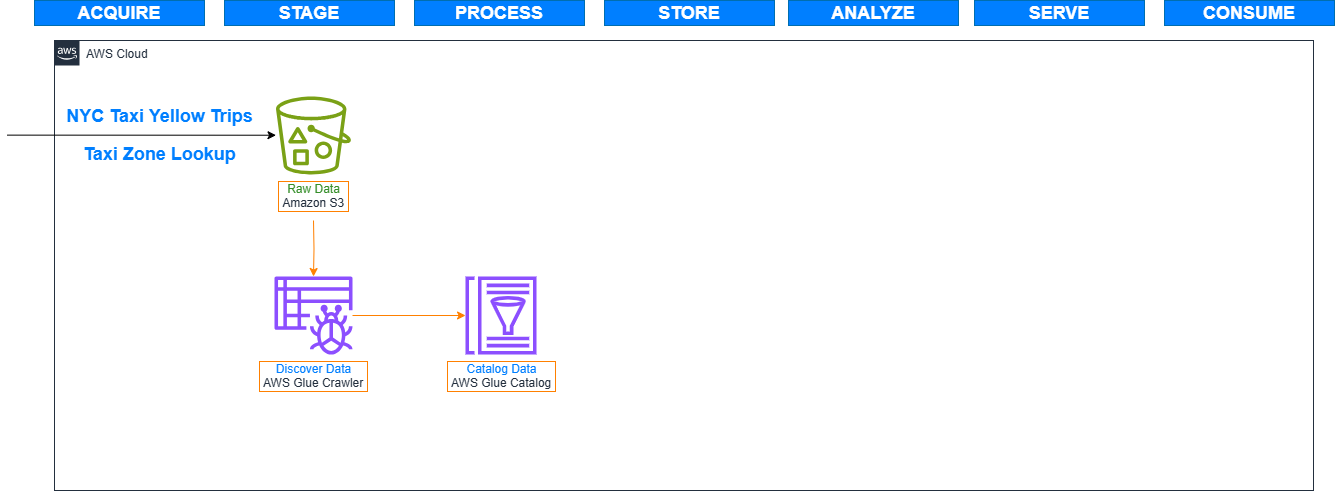
With an array of data sources and formats in your data lake, it’s important to have the ability to discover and catalog it order to better understand the data that you have and at the same time enable integration with other purpose-built AWS analytics.
In this lab, we will create an AWS Glue Crawlers to auto discover the schema of the data stored in Amazon S3. The discovered information about the data stored in S3 will be registered in the AWS Glue Catalog. This allows AWS Glue to use the information stored in the catalog for ETL processing. It also allows other AWS services like Amazon Athena to run queries on the data stored in Amazon S3.
Introducing AWS Glue
AWS Glue is a fully managed serverless extract, transform, and load (ETL) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores. AWS Glue consists of the following core components:
- Data Catalog – a central repository to store structural and operational metadata of your data assets.
- ETL Engine – automatically generate Scala or Python code.
- Jobs System – provides managed infrastructure to orchestrate your ETL workflow.
AWS Glue also includes additional components like:
- AWS Glue DataBrew - A visual data preparation tool that makes it easy for data analysts and data scientists to prepare data with an interactive, point-and-click visual interface without writing code.
- AWS Glue Elastic Views - Build materialized views that combine and replicate data across multiple data stores without you having to write custom code.
Together, these automate much of the undifferentiated heavy lifting involved with discovering, categorizing, cleaning, enriching, and moving data, so you can spend more time analyzing your data.